En collaboration avec :
Présentation
Présentation du contexte
La société "Air Paradis" souhaite pouvoir détecter les bad buzz via le réseau Twitter. Pour ce faire, Air Paradis requête une entreprise de conseil spécialisée sur les problématiques du marketing digital (dont je fais partie en tant qu'ingénieur IA) pour obtenir une solution lui permettant d'obtenir le sentiment associé à un tweet.
Pour ce faire l'entreprise ne dispose pas de jeu de données. Le jeu de données sera donc un jeu de données présent sur Kaggle : "Sentiment140 dataset with 1.6 miilion tweets" qui met à disposition 1.600.000 tweets labellisés avec un sentiment (négatif ou positif). Faisant partie d'une entreprise de conseil spécialisée sur les problématiques du marketing digital, mon responsable "Marc" souhaite que je généralise la solution et que je benchmark des solutions cloud (Azure) pour voir l'impact/l'utilité/la performance de ces solutions par rapport à des solutions proposées par un Ingénieur IA grâce à des algorithmes de Deep Learning.
Présentation rapide du jeu de données
Le jeu de données source contient 6 colonnes (target, id, date, flag, user, text) et pour chaque ligne un tweet associé (colonne "text"), cependant seulement 2 colonnes sont intéressantes dans note contexte. On prendra donc la colonne "target" qui indique le sentiment associé aux tweets (0 pour un tweet négatif et 4 pour un tweet positif) et également la colonne "text" qui correspond aux tweets.
Le jeu de données est une extraction de 3 mois de tweets et les tweets sont compris entre 1 et 150 mots.
Azure Machine Learning & Cognitive Service
Azure fourni un espace de travail pour le Machine Learning qui comprend une architecture proposant de nombreux services comme la création de pipeline ML, la création d'un modèle automatique (Automated ML), ou encore de créer des instances web/inférence pour mettre en place une API réalisée depuis Automated ML, studio drag & drop ou encore un notebook Azure ou local.
Le schéma ci-dessous est une représentation de l'architecture fournie par Azure Machine Learning, on y retrouve les composantes (dependencies) qu'utilisent Azure Machine Learning (qui sont demandées lors de la création), les ressources managées (Container ACI/ Cluster AKS), et le plus important les possibilités du workspace, avec la création d'environnements (il existe déjà des environnements pré-définis), des "Experiments" qui permettent l'entraînement de modèle, la création de pipeline complète le stockage de modèle et jeu de données et enfin la mise en place d'Endpoint pour exposer les différents modèles créés.

Il existe également un service Clé en main "Cognitive Services Azure" qui est une API permettant de faire de la traduction de texte, détection de langage, Data Mining, Vision par ordinateur... On abordera cette solution plus en détail dans la partie Réalisation des solutions.
Comment utiliser Azure ?
Cette section n'a pas pour but de connaître toutes les ressources Azure, mais uniquement celle abordée ici (Azure Machine Learning), pour commencer, il faut créer une ressource Azure Machine Learning et remplir les champs suivants :
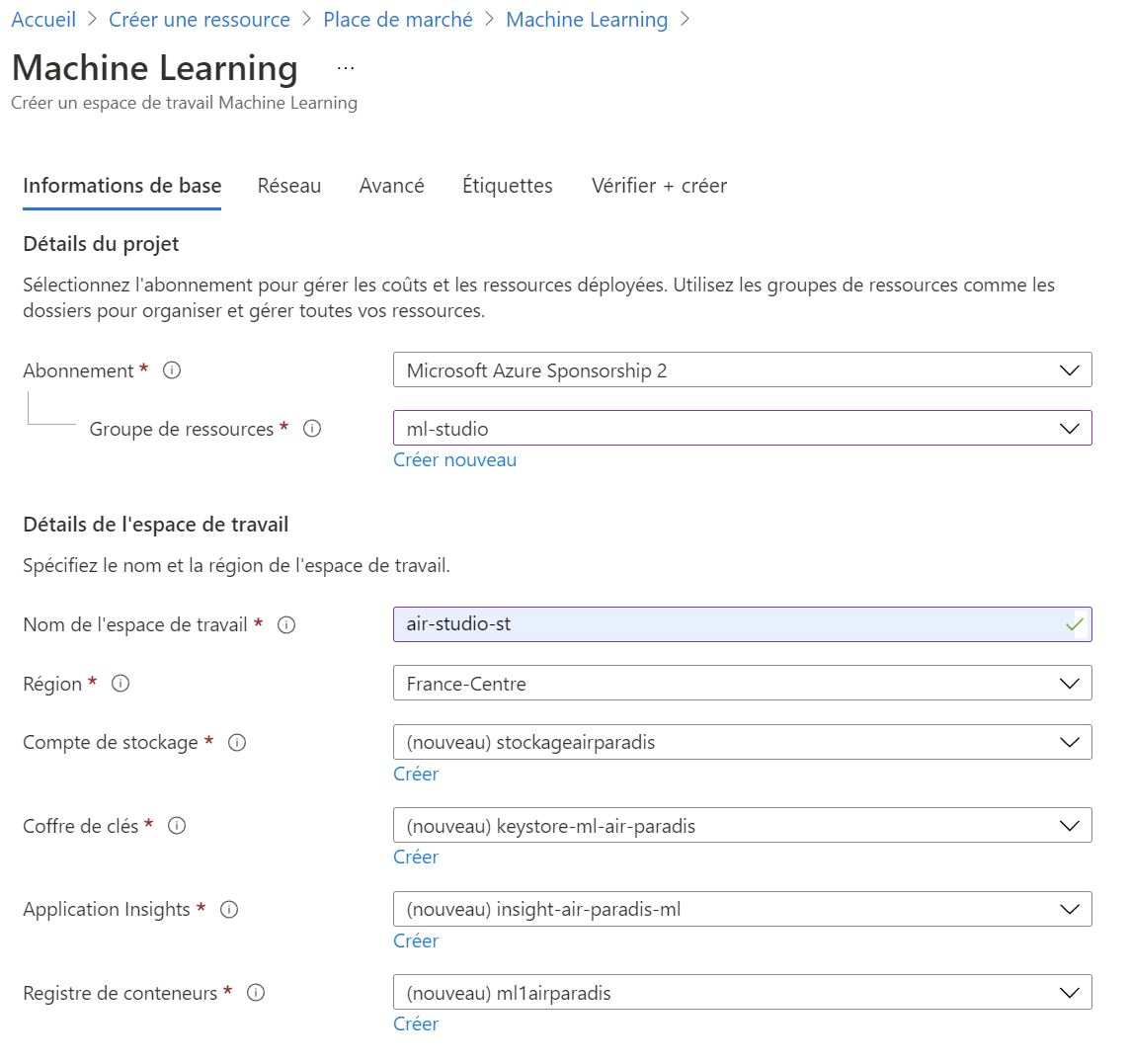
Il est possible d'utiliser des ressources déjà créées préalablement ou bien créer directement les ressources nécessaires depuis cette interface (voire même laisser la création se faire automatiquement).
Comme précisé, les ressources présentent ici sont nécessaires au fonctionnement d'Azure Machine Learning, le Compte de Stockage permet de stocker les ressources générées par Azureml comme les notebooks, les environnements, les modèles... Le container Registry permet le management des ressources de calcul ACI et AKS, de paire avec Azure Key Vault et Azure Application Insight.
Après avoir créé notre ressource, on peut exécuter Azure Machine Learning Studio :
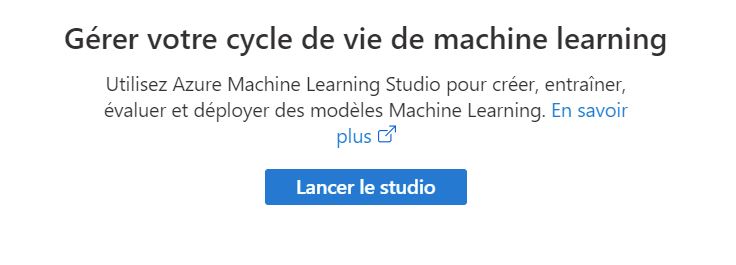
Depuis cet outil, il est possible de créer un notebook, faire des "Pipelines"/"Experiments" avec "Designer", et également créer automatiquement un modèle de Machine Learning 1 click dans la partie "Automated ML" puis de déployer le modèle également en 1 click :
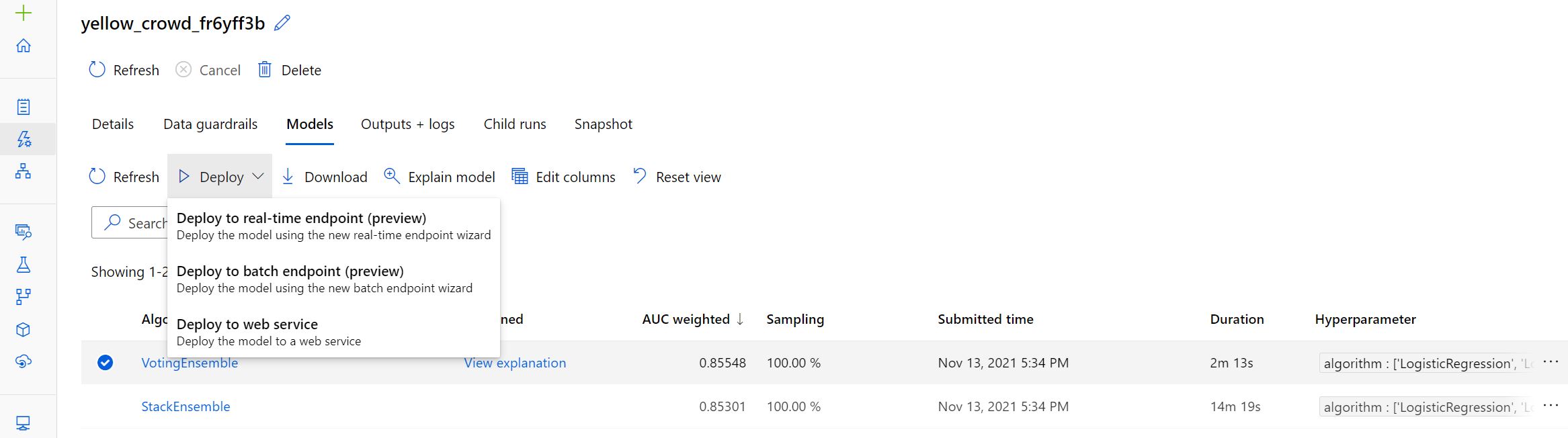
Réalisation des solutions
Pour la réalisation des tests, j'ai créé un jeu de données de 4000 tweets stratifiés avec 2000 bad tweets et 2000 good tweets. Dans chacun des résultats présentés ci-dessous le jeu de données a été séparé avant tout traitement. Cela permet d'éviter les fuites de données et de bien séparer le jeu de test et d'entraînement.
Cognitive Service Azure
Pour cette partie, rien de complexe étant une solution clé en main, pour créer une ressource cognitive, il suffit de se rendre sur le portail azure et de créer une ressource Cognitive Services.
Une fois créé, il suffit de récupérer le "Endpoint" et "Keys" d'accès au service, après ça, il suffit de suivre la documentation pour l'implémenter puis l'utiliser.
Pour sécuriser l'accès, on peut mettre les accès en variable d'environnement puis on utilise la méthode suivante pour se connecter au Cognitive Service :
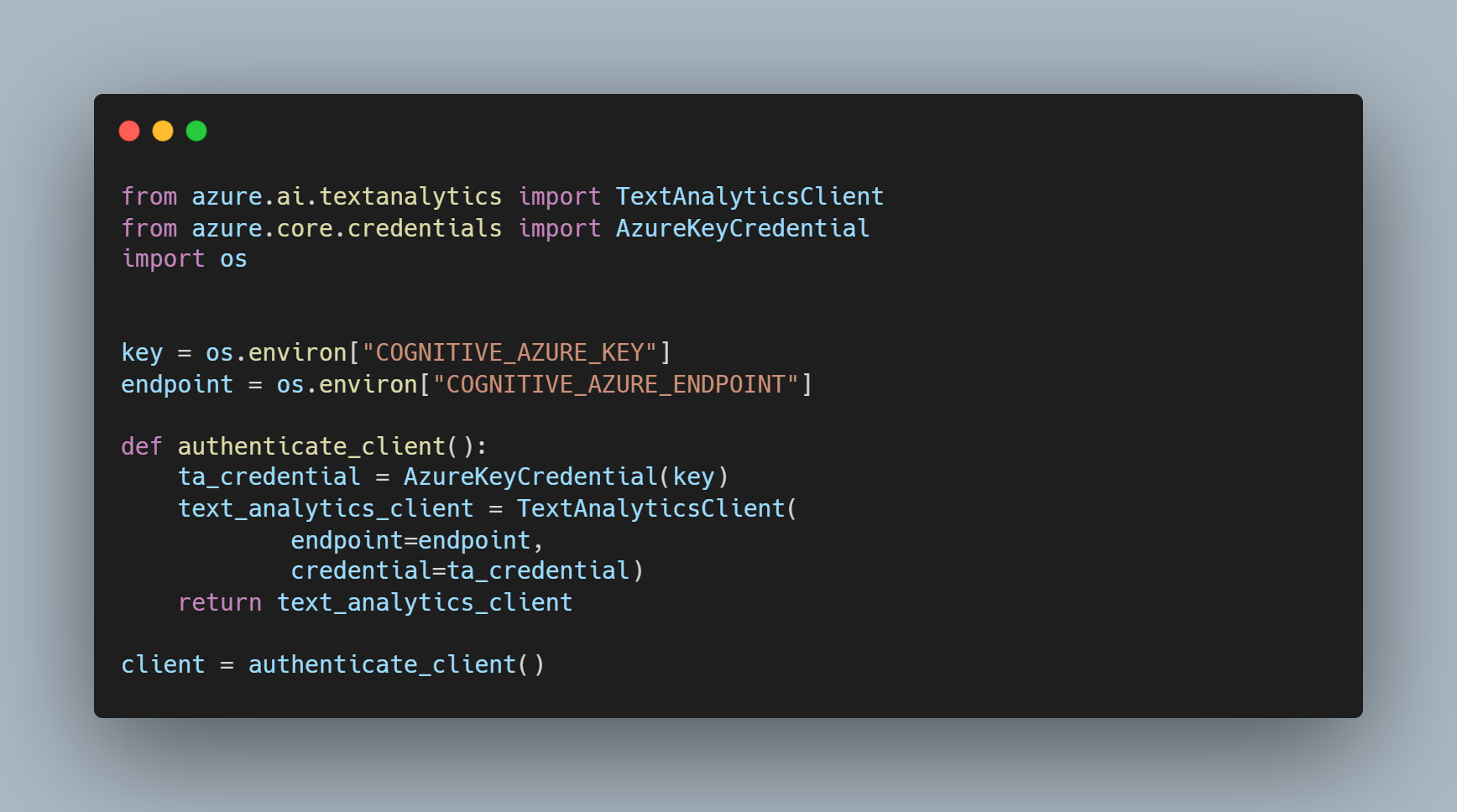
Après ça, on peut faire appel simplement à l'API avec ces méthodes :
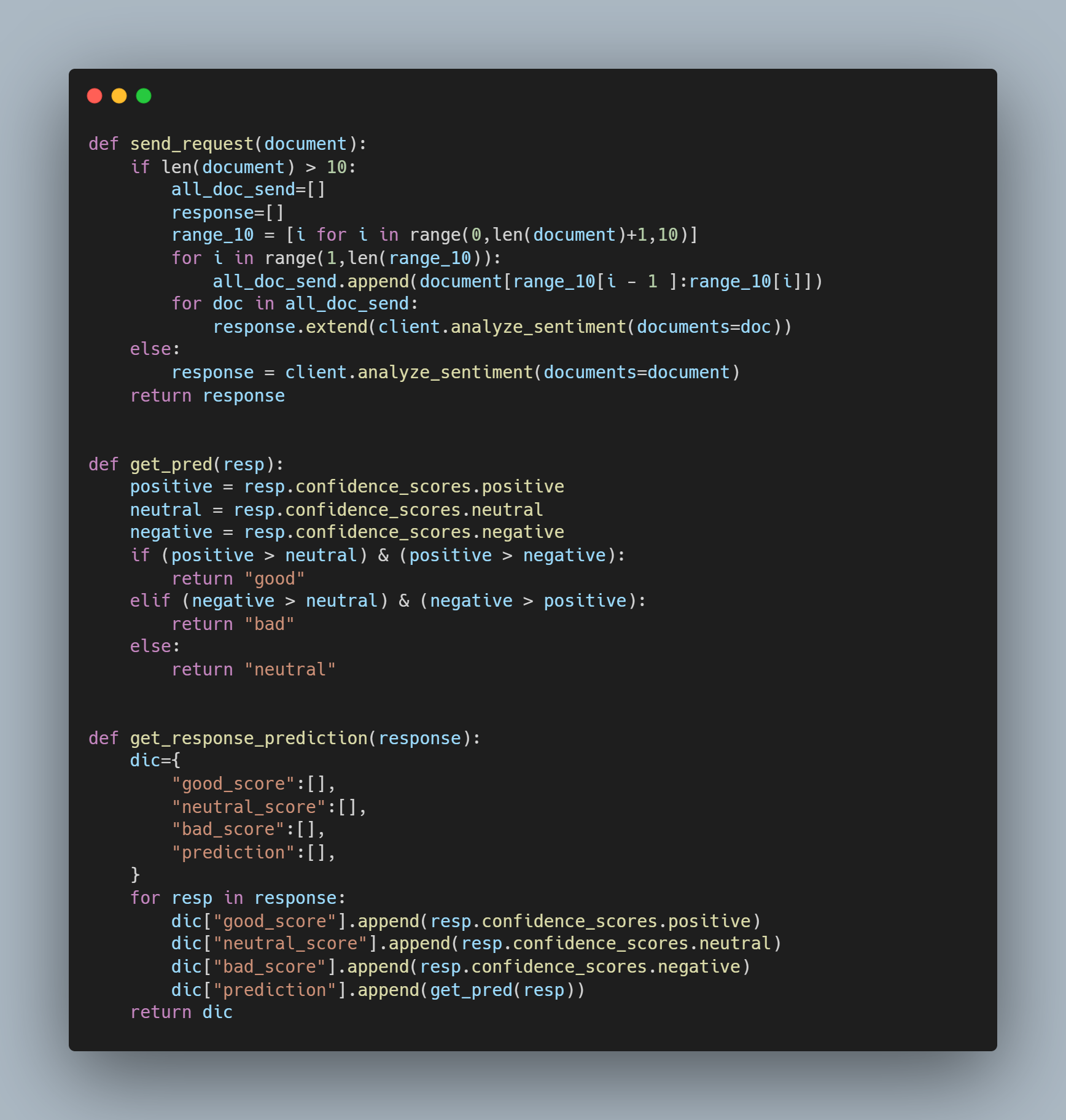
Puis on récupère les réponses de l'API avec : dic_response= get_response_prediction(send_request(data)).
Ce service nous retourne 4 informations, la prédiction (neutral, bad, good) puis le score associé (bad, neutral, good).
Comme notre jeu de données contient uniquement des données binaires (bad/good) on utilisera une régression logistique sur les 3 scores du service pour prédire les labels binaires associés et pouvoir obtenir un score de sentiment de mauvais à bon tweet et une réponse binaire.
Voici les résultats du service cognitif :
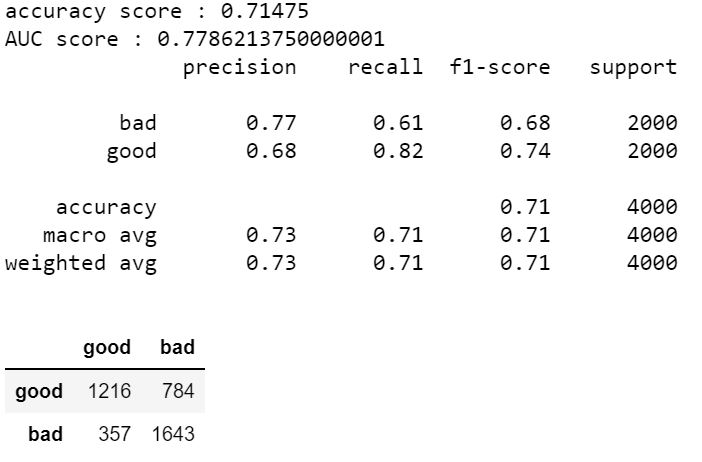
On obtient un score AUC de 0.77 ce qui reste correct pour un service généraliste qu'offre le Cognitive Service. Si on regarde en détail, on remarque cependant un point très positif sur la matrice de confusion, le Cognitive Service détecte très bien les "bad" tweets avec une précision de 0.77.
On utilisera ce modèle comme "Baseline" afin de comparer l'utilité d'investir du temps dans la création d'un modèle personnalisé.
Module "no-code"
Sur Azure, il existe 2 modules "no-code", une version drag & drop que l'on va présenter en détail puis une version automatique (Automated ML) qui créé un pipeline/modèle complet en 1 click depuis Azure Machine Learning déployable également en 1 click.
Pour faire le pipeline drag & drop, on utilisera la version "classique" de "azureml" (/!\ cette version sera supprimée en 2024 /!\).
Il est possible également de réaliser une pipeline sur la nouvelle version (avec un tutoriel sur la création ET un tutoriel sur le déployement) mais il est nécessaire de créer une instance de calcul pour réaliser la pipeline
puis utiliser un container ACI ou cluster AKS pour le déployement qui sont payants...
Pour le module drag & drop "classique" "studio.azureml.net" il suffit de créer une nouvelle expérience puis de déplacer les modules que l'on souhaite appliquer sur notre pipeline comme
le montre le gif ci-dessous (le gif présente la nouvelle version sur Azure Machine Learning, mais le fonctionnement est identique).
Pour ce module, j'ai réalisé un algorithme "simple" de Régression Logistique.
Pour ce faire, j'ai d'abord :
- Importer le jeu de données que j'ai stocké dans un compte de stockage Azure (fichier Blob) qui contient un échantillon réduit du jeu de données (10.000 tweets parfaitement stratifiés entre les bons et mauvais tweets). 1
- Après ça, j'ai effectué un nettoyage des données textuels en supprimant les URL, faisant de la lemmatization, supprimant les stop words... 2
- J'ai ensuite créé ma matrice TF-IDF et généré un jeu de données du vocabulaire que j'ai réutilisé par la suite. 3
- Puis j'ai entraîné mon jeu de données grâce à cette matrice TF-IDF et je renvois ensuite les résultats du modèle. 4
Ci-dessous voici la pipeline complète utilisée pour le déploiement :
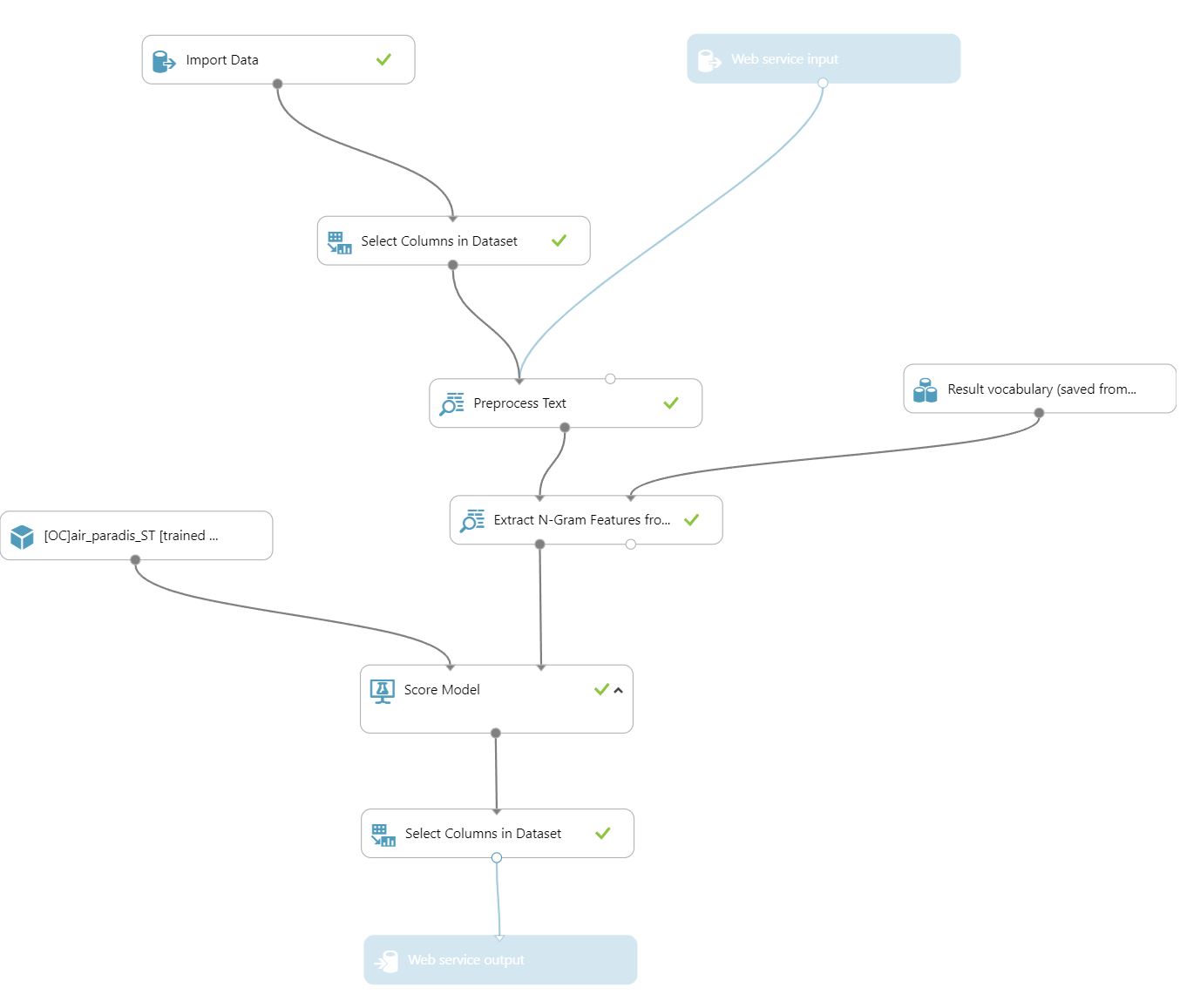
Les résultats sont moins bons que le cognitive service, mais pourrait être équivalent/meilleur si le jeu de données serait plus important.
Algorithme avancé
Démarche des recherches
- La première étape ici consistera à vérifier la pertinence de faire de la lemmatisation ou du stemming pour l'amélioration d'algorithme de DL type. (Embedding -> LSTM -> Dense)
-
Après ça, on effectuera un benchmark de plusieurs types d'algorithmes DL afin de trouver la meilleure structure :
- Modèle DL multicouche
- Modèle RNN classique
- Modèle LSTM Embedding généré automatiquement
- Modèle LSTM avec Word2Vec
- Modèle LSTM avec Glove
- Modèle Pré-entraîné BERT (Transfer-Learning)
- Après avoir analysé plusieurs modèles, on choisira un modèle afin de l'optimiser.
- Une fois la recherche d'hyperparamètres effectuée, on générera notre modèle final grâce à une Pipeline.
Résultats
Pour faire un résumé simple, les structures LSTM apportent de bien meilleurs résultats que les RNN ou des modèles classiques multicouches. Ensuite les méthodes de Lemmatization et Stemming font perdre de l'information et donc ici de la performance.
Un clean classique avec simplement du regex apporte de meilleurs résultats voire même ne pas traiter le texte en amont !
Pour les structures Embedding, la méthode Word2Vec semble plus performante, et enfin Bert pré-entraîné obtient de très bons résultats, mais reste moins performant que Word2vec avec une couche LSTM.
Il serait également possible de ré-entraîner la couche Bert avec le système d'attention BERT qui est parfaitement explicité sur le site "Les Dieux du code".
Au final, le meilleur est le Modèle LSTM avec la couche Embedding Word2Vec, et voici les résultats sur le jeu de données test :
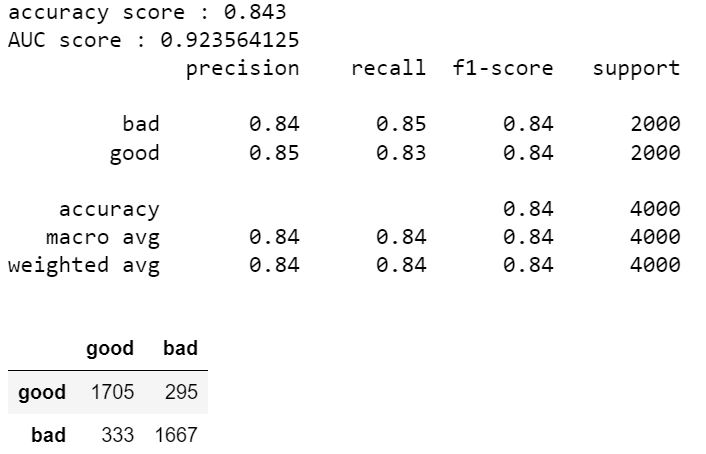
Ce modèle est meilleur en tout point avec un score AUC de 0.92 et 0.84 de précision sur les bad tweets !
Pour les curieux les tests et benchmarks entre les différentes structures de Deep Learning sont explicités sur mon Github.
Déploiement Azure
Pour le déploiement Azure, il existe plusieurs solutions, ici, on utilisera l'environnement Azure Machine Learning pour faire le déploiement de notre modèle.
Bien évidement il faut avoir créé un workspace Machine Learning sur Azure (comme expliqué dans le chapitre "Comment utiliser Azure ?").
Pour déployer son modèle, il faut préalablement sauvegarder son modèle (avec joblib au format .pkl ou bien save un model Keras avec la méthode keras_model.save("./data/model/keras_model") et non au format h5).
Après ça, on peut se connecter à son workspace Machine Learning Azure. Pour ça, il est nécessaire d'installer la librairie "azureml" pip install azureml & pip install azureml-core puis de se connecter de la façon suivante :
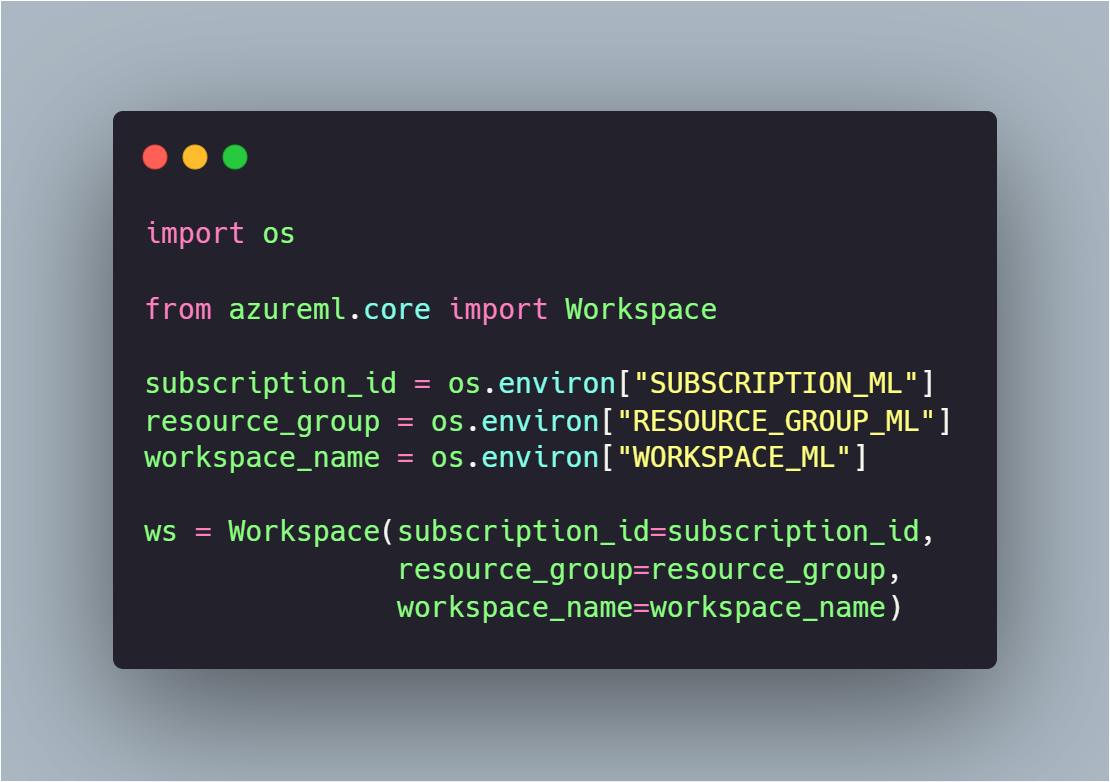
Après avoir la connection avec le workspace, on peut interagir avec, et donc en premier lieu sauvegarder son modèle sur notre workspace.
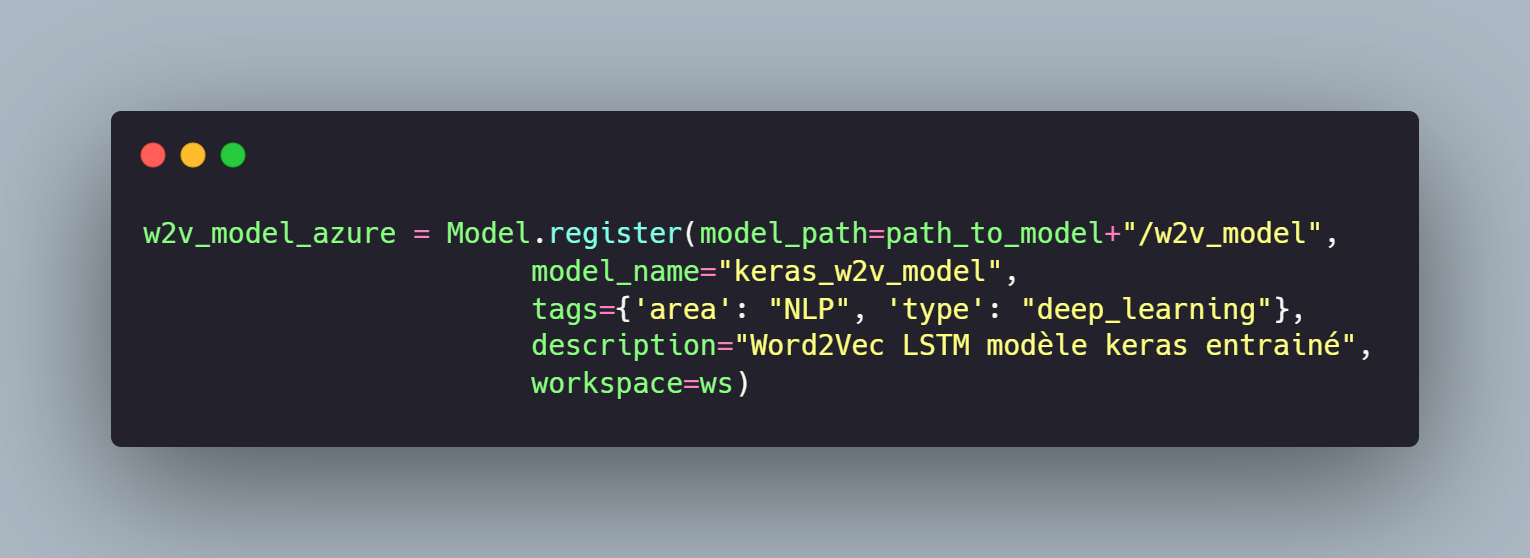
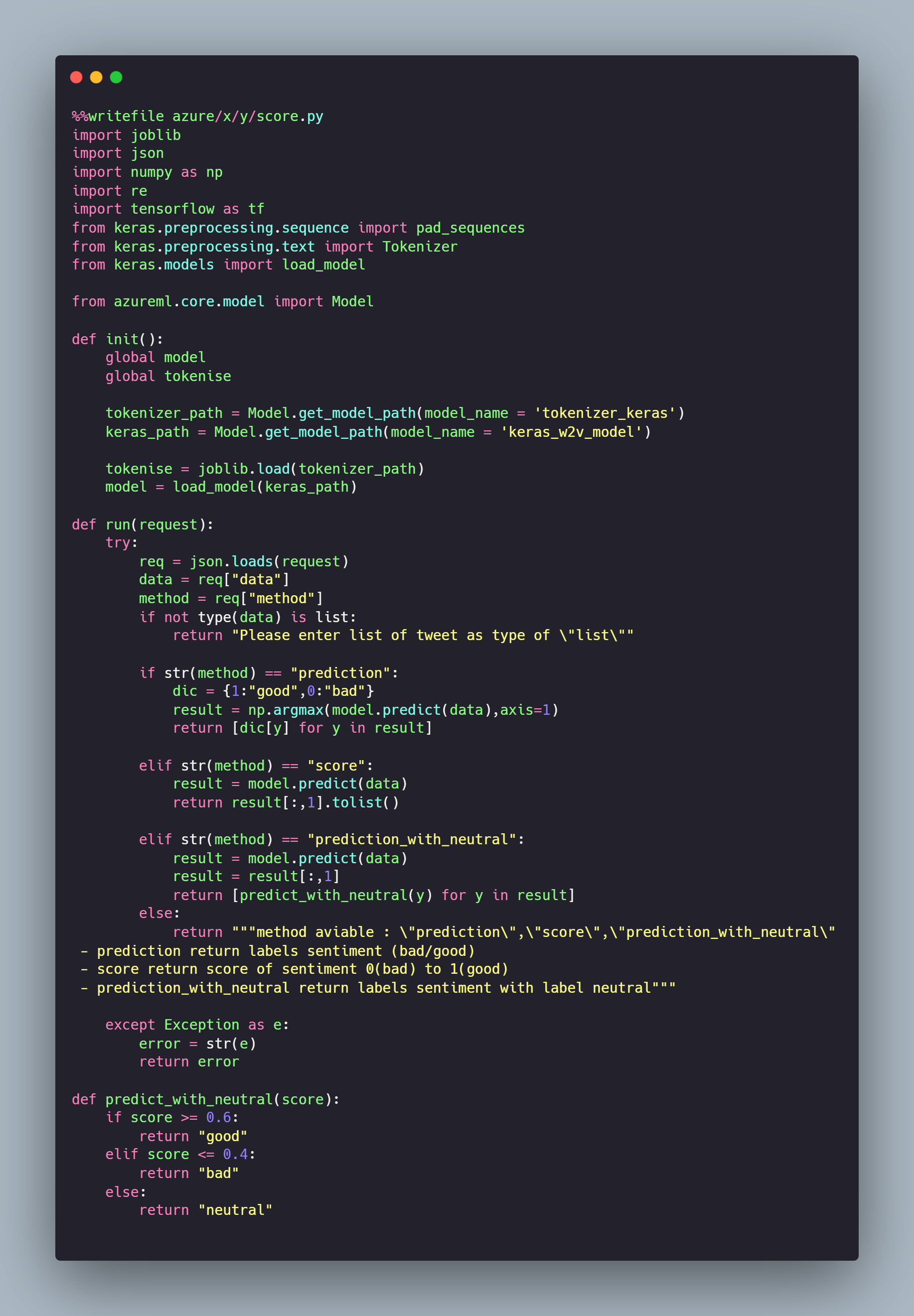
Cette méthode upload notre modèle dans le workspace puis renvoie son objet "azureml.Model" qui nous servira par la suite (il est également possible de récupérer un modèle avec le code w2v_model_azure = Model(ws, 'keras_w2v_model')). Pour interagir avec notre modèle qui sera déployé, il est nécessaire de créer un fichier score.py, le container généré se basera sur ce fichier lors du déploiement pour interagir avec les modèles sous la forme d'une API. En voici un exemple qui récupère le modèle de Deep Learning entraîné et le Tokenizer Keras entraîné dans la fonction init() qui est exécutée au déploiement du container, puis la méthode run qui est exécutée sur l'appel de l'API :
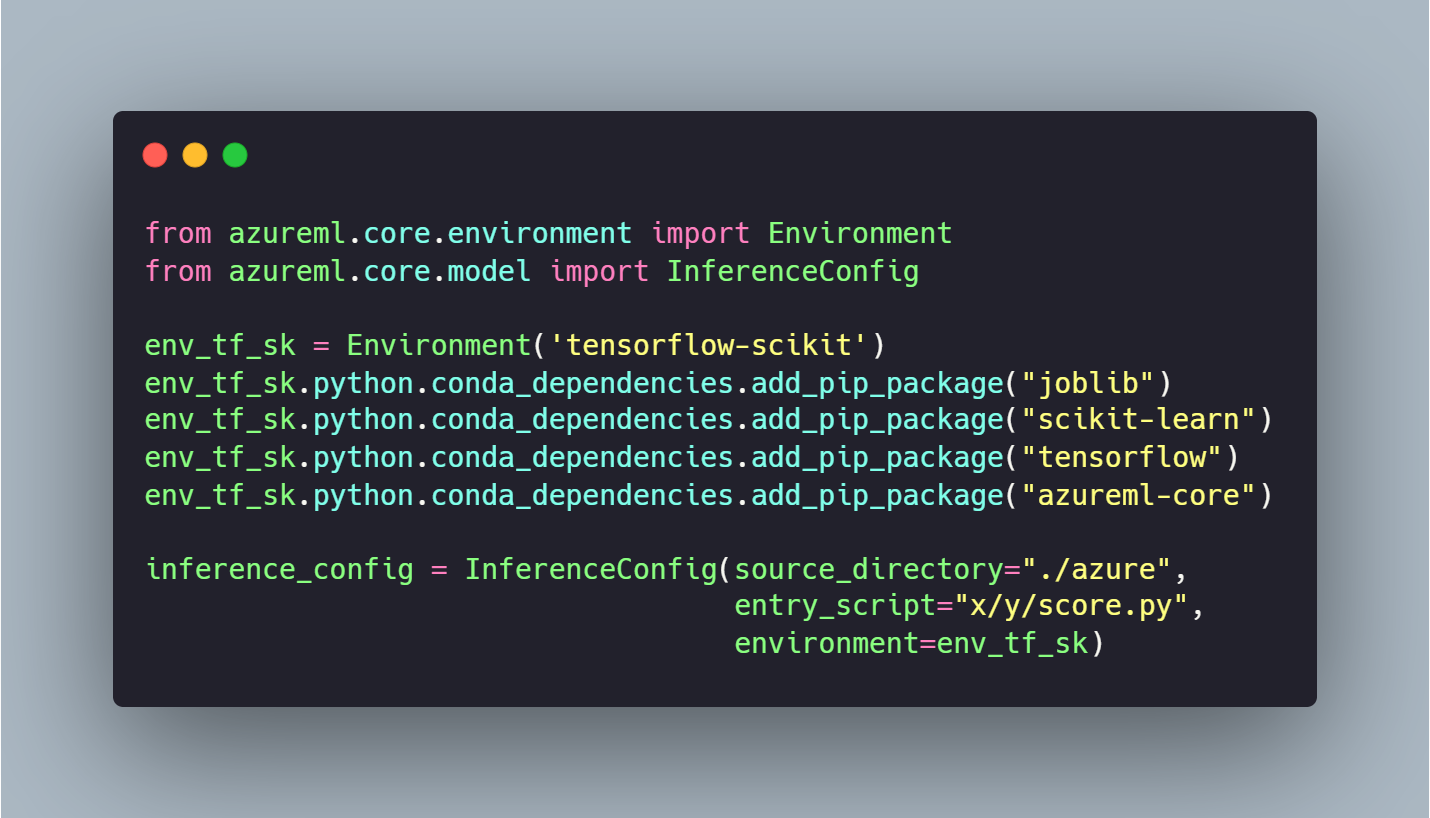
Comme précisé à l'instant, il est nécessaire d'avoir un environnement d'exécution, il existe plusieurs méthodes comme la création d'un Container pré-créé, utiliser des environnements pré chargé par Azure ou encore créer son propre environnement grâce à la méthode suivante :
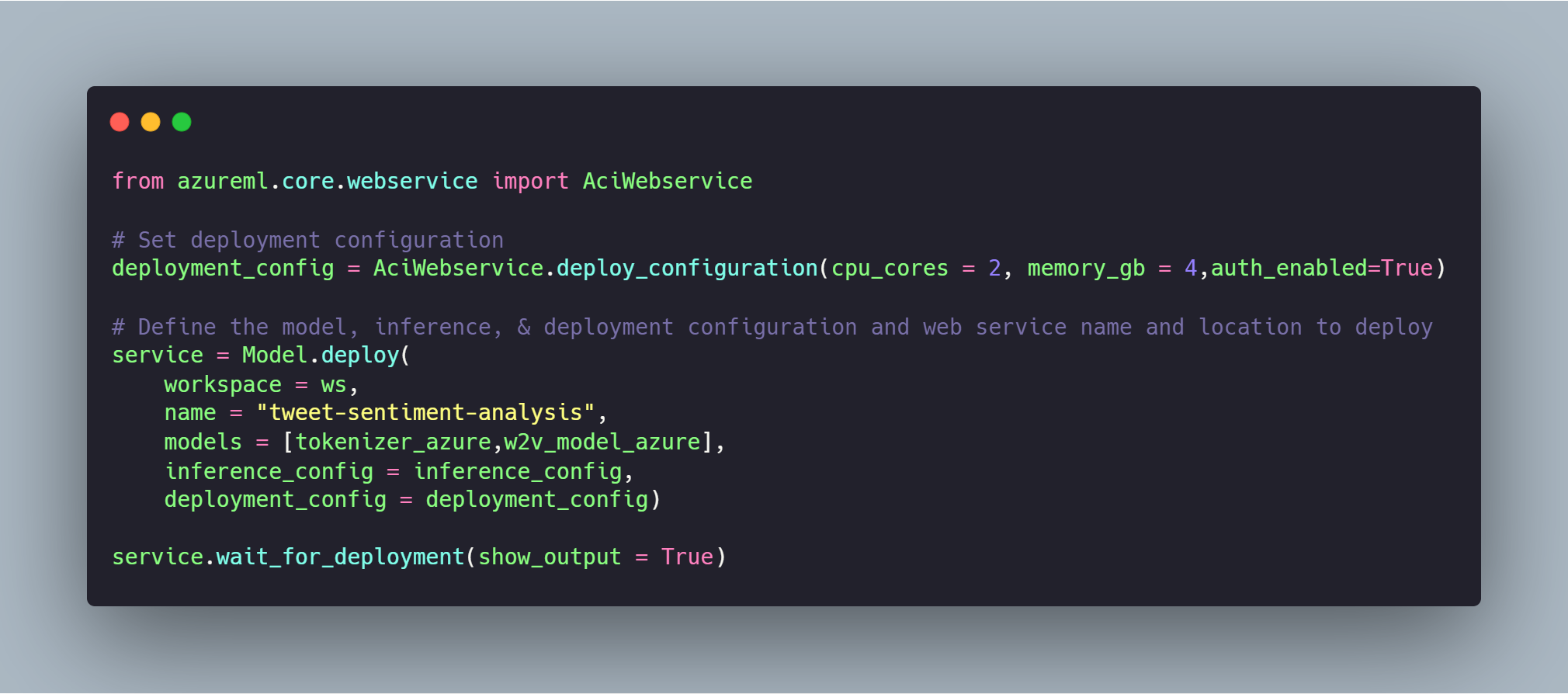
Maintenant que nous avons tous les Objects à disposition. Il est nécessaire de préparer la configuration de déployement (AKS / ACI). Ici, on utilisera un container simple ACI avec 2 core et 4Go de ram.
Il ne reste plus qu'à déployer nos modèles (Keras & Tokenizer):
Présentation des résultats
Performance des modèles
Voici le résultat des différentes solutions testées en terme de performance:
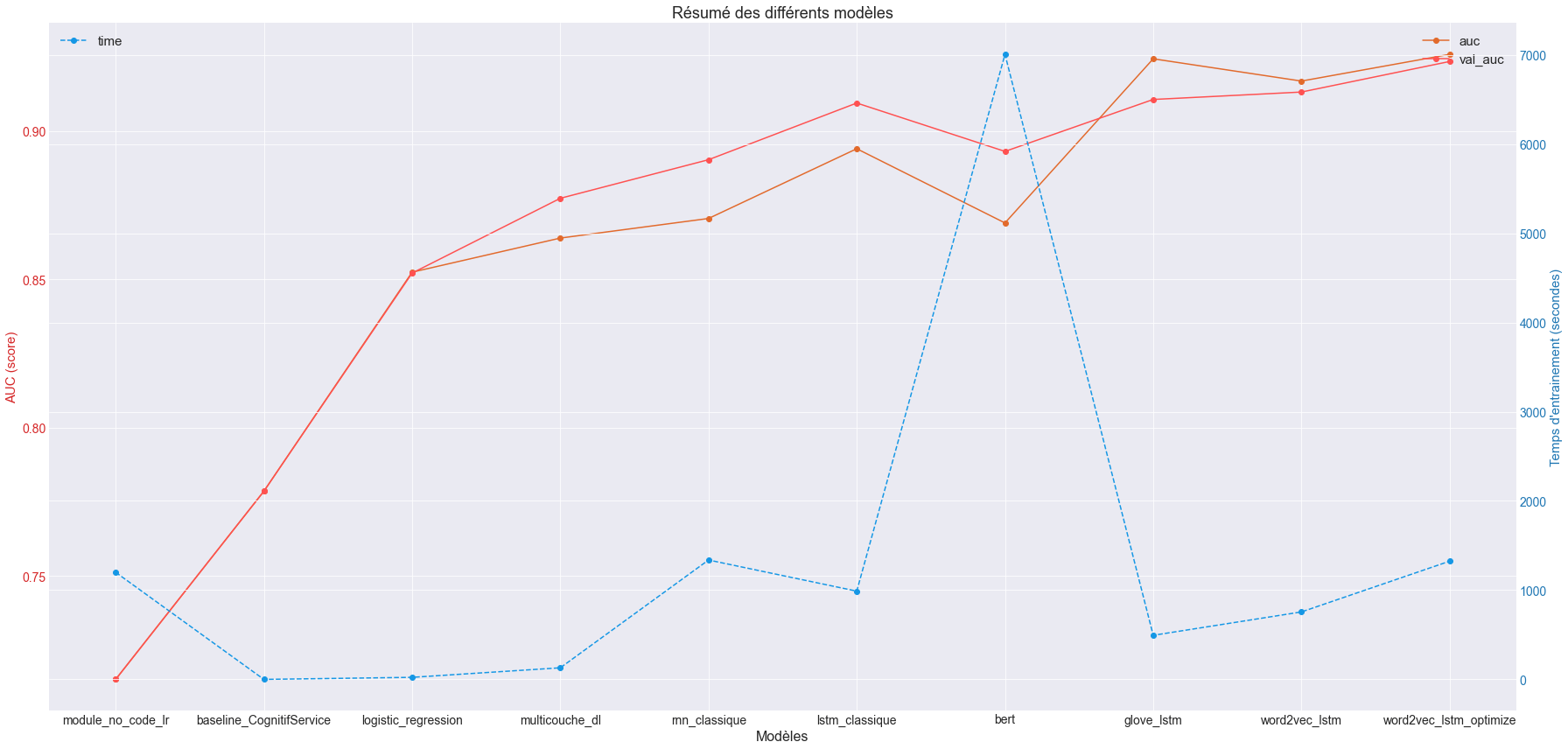
Cette fiche résumé est suffisamment parlante, on voit que les modèle word2vec_lstm et meilleur que tous les autres modèles (Glove est meilleur à l'apprentissage, mais généralise moins bien que Word2Vec).
Bert peut largement être amélioré, mais on voit que le temps d'entraînement avec un modèle pré-entraîné est déjà très important, je ne suis donc pas partie sur cette solution pour ne pas prendre plusieurs jours sur l'apprentissage.
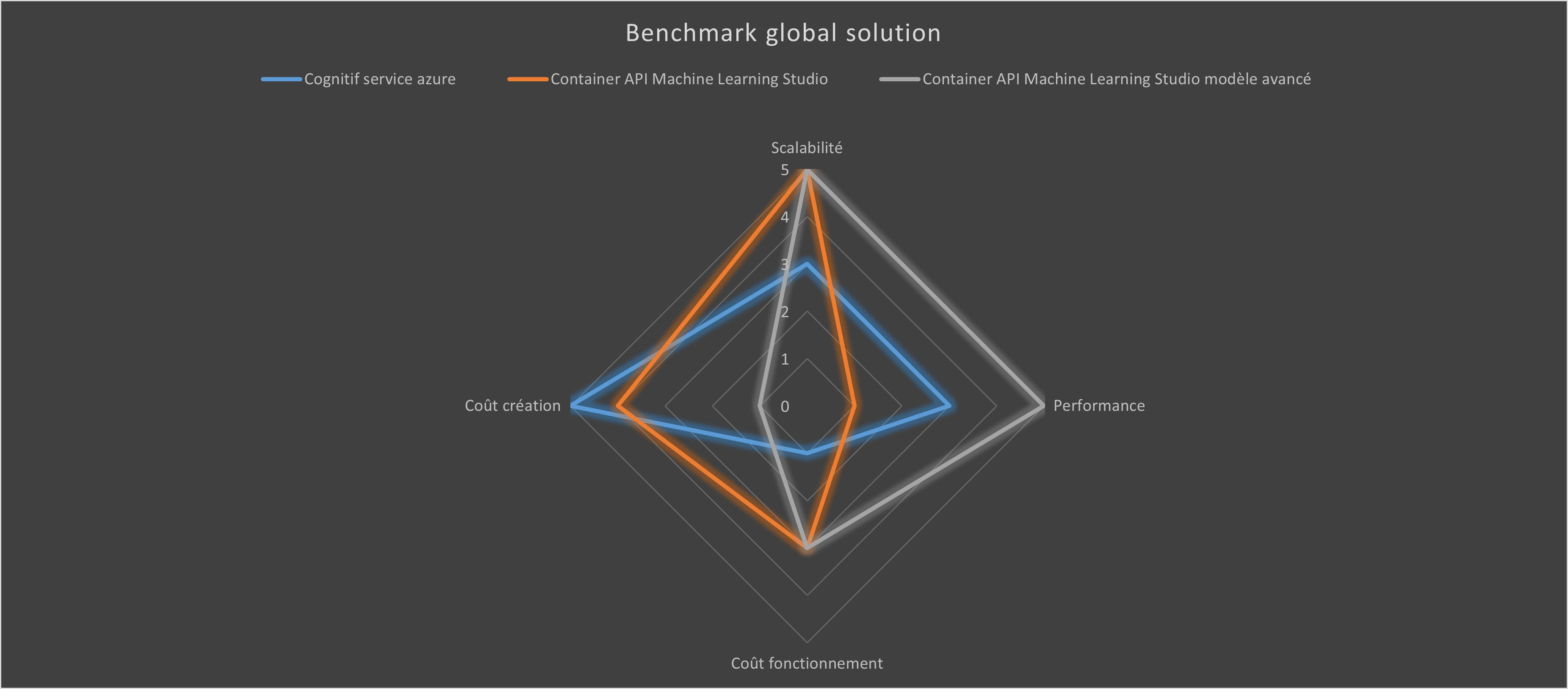
Coût d'utilisation
Voici les fiches de coût estimées pour une utilisation à 1.000.000 de tweet mensuel:
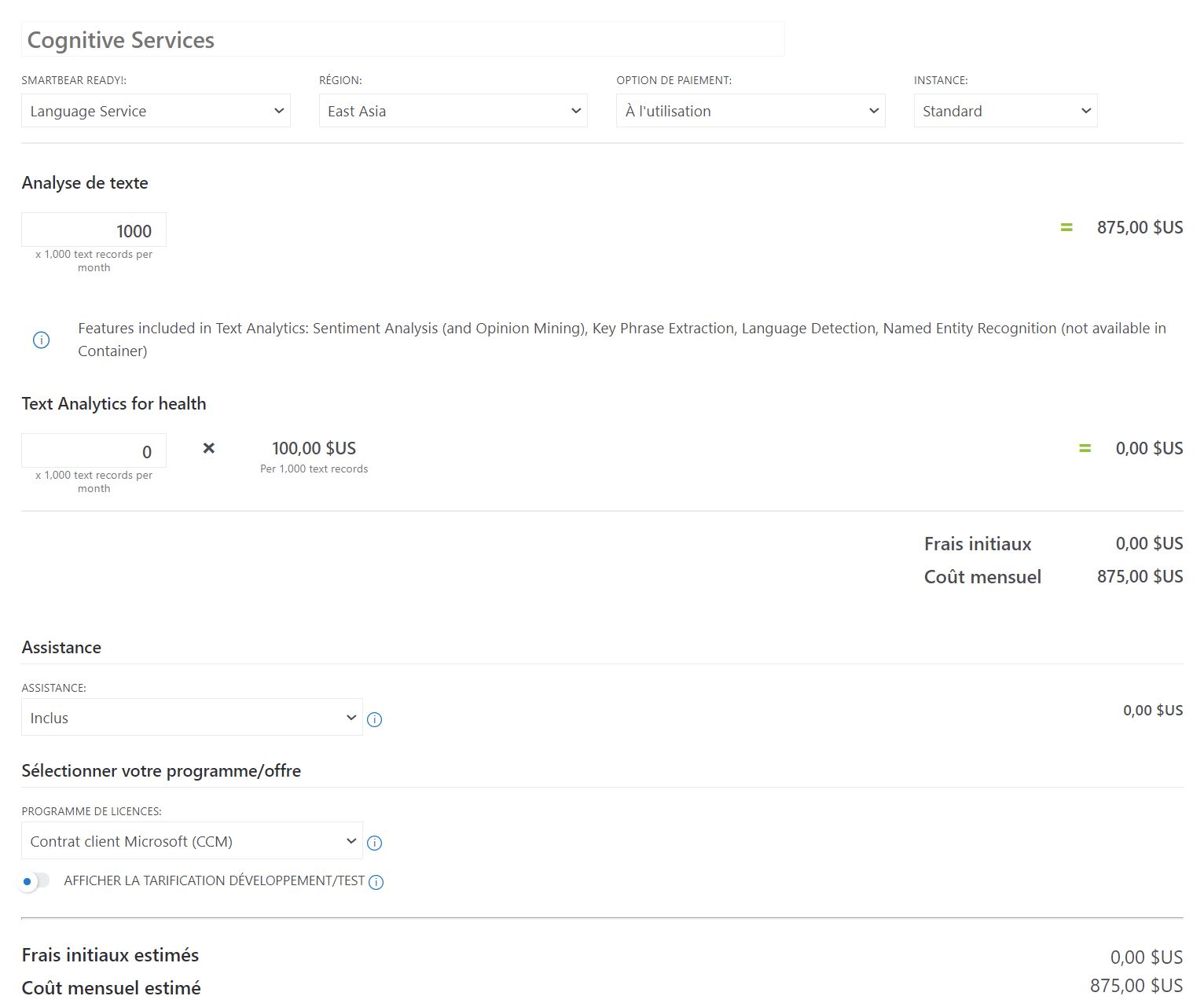
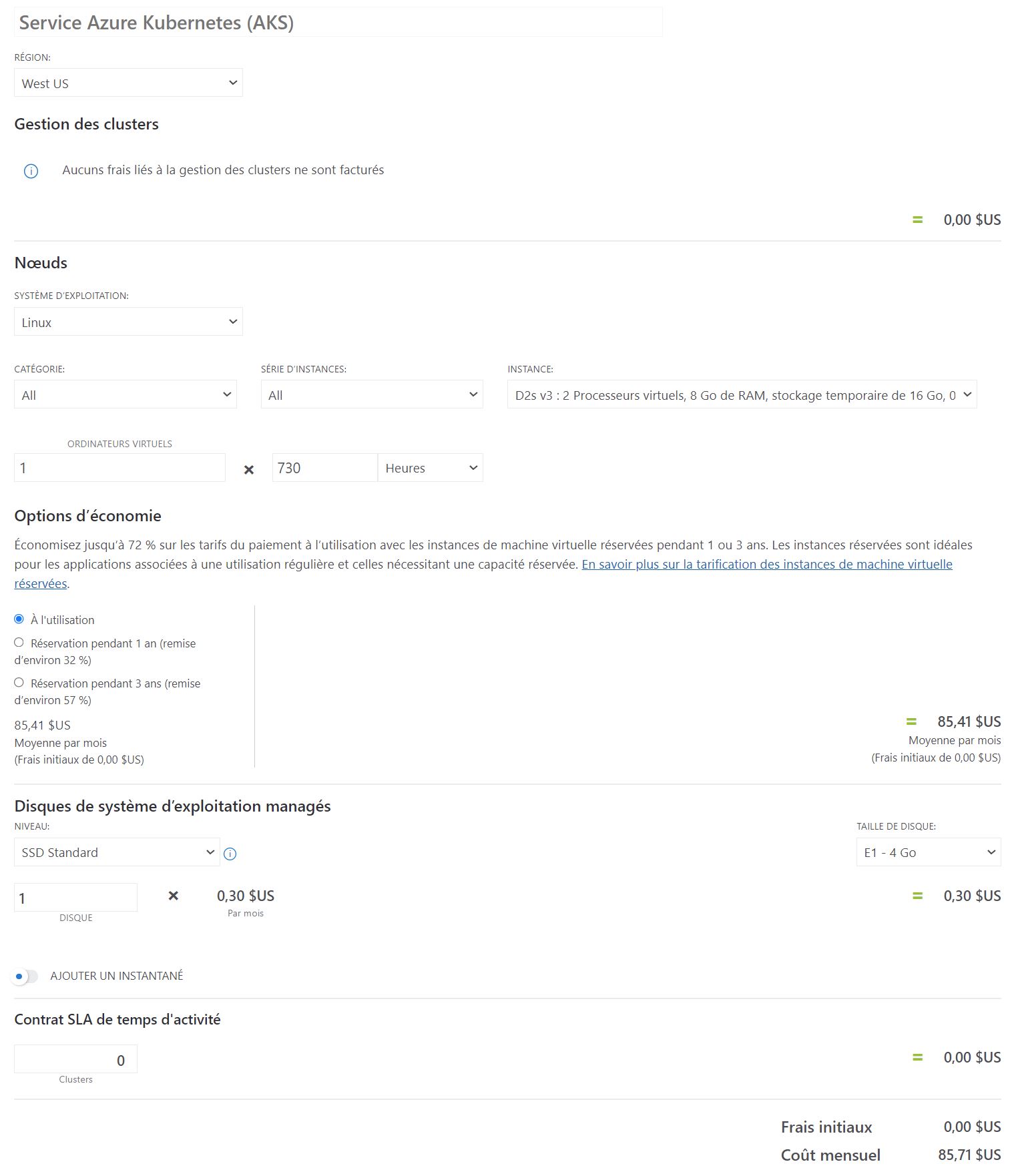
J'ai réalisé un fichier Excel pour simuler les coûts du projet disponible ici en téléchargement.
Conclusion
Si on réalise une matrice de choix, le plus pertinent est le modèle avancé malgré son coût de mise en place le plus important (prix d'un Ingénieur IA/consultant Data pour travailler sur le sujet), il obtient les meilleurs résultats et un coût d'utilisation (à forte utilisation) assez faible en production !
Le détail du code est présent sur Github avec le script de déploiements, les différentes modélisations avancées et les requêtes et benchmark du module no-code et du Cognitive Service Azure.